5.7.2 Prediksjonsverdier og residualverdier
Når man kjører binære regresjonsanalyser gjennom kommandoene logit eller probit, er det to måter å hente ut prediksjonsverdier på. Den ene måten er gjennom bruk av kommandoen logit-predict eller probit-predict som kan brukes til å generere en ny variabel med individuelle prediksjonsverdier, sansynlighetsverdier eller residualverdier (ikke probit-predict). Disse kan brukes til videre input til ulike statistiske formål. Den andre måten er å benytte opsjonen margins() som returnerer en ferdig utregnet prediksjonsverdi for responsvariabelen målt ved gjennomsnittet for alle forklaringsvariablene som inngår.
Generere ny variabel med individuelle prediksjons-, sannsynlighets- eller residualverdier
Alle regresjonsvarianter som finnes i microdata.no har tilknyttede kommandoer som genererer blant annet residual- og prediksjonsverdier. Dette er verdier som kan brukes til å analysere dataspredningen og for testing av regresjonsmodeller. Prediksjonsverdier kan dessuten brukes som input til videre analyser.
Kommandoene har samme navn som tilhørende regresjonskommando pluss -predict.
Syntax:
logit-predict <variabel> <variabelliste> [if <betingelse>] [,<opsjoner>]
probit-predict <variabel> <variabelliste> [if <betingelse>] [, <opsjoner>]
Variablene angis på samme måte som for den tilhørende regresjons-modellen som kjøres med kommandoen logit evt. probit.
Følgende verdier kan hentes ut:
-
logit-predict: Sannsynlighetsverdier, prediksjonsverdier og residualer -
probit-predict: Sannsynlighetsverdier og prediksjonsverdier
En bestemmer selv hvilke verdier en vil generere gjennom bruk av opsjoner. Resultatet av kjøringene er et sett med variabler som inneholder de ulike verdiene. Som standard genereres førstnevnte verditype i listen over, men det anbefales likevel å spesifisere dette gjennom opsjoner ettersom en da også kan bestemme navn på de genererte variablene inni en parentes som vist i syntax-eksempelet nedenfor. Om en kjører flere -predict-kommandoer, må en lage nye navn for de automatisk
genererte variablene.
Syntax-eksempel:
logit-predict høylønn alder mann formue, residuals(res4) predicted(pred4) probabilities(prob4)
De automatisk genererte variablene kan brukes som input til videre analyser eller til å vises grafisk. Aktuelle grafiske kommandoer er hexbin og histogram. Ved å kjøre histogram på residualvariabelen, kan en sjekke hvorvidt residualene er normalfordelte. Hexbin-kommandoen kan dessuten brukes til lage anonymiserte spredningsplott der en kombinerer to sett med verdier.
For mer detaljer anbefales det å bruke kommandoen help logit-predict eller help probit-predict.
Eksempel: Analyse av prediksjons- og residualverdier
Beregne predikert verdi for responsvariabel målt ved gjennomsnittet for forklaringsvariablene
Ved å bruke opsjonen margins() når du kjører binære/logaritmiske regresjonsmodeller gjennom kommandoene logit eller probit, kan du enkelt finne ferdig beregnet predikert verdi for responsvariabelen (Y) målt ved gjennomsnittsverdien for alle de respektive forklaringsvariablene.
Eksempler:
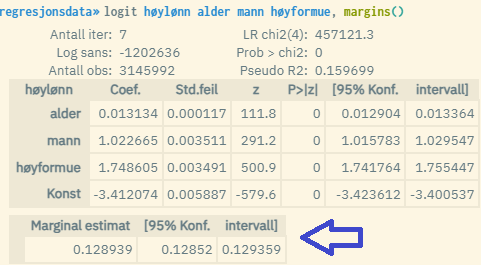
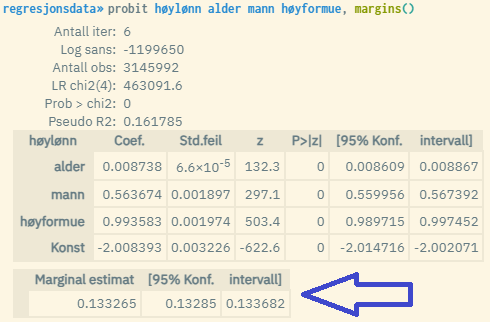
Det som da blir returnert under modellestimatene er den predikerte Y-verdien samt konfidensintervallet. «Marginal estimat» (altså predikert Y) kan tolkes som «forventet verdi av Y målt for en gjennomsnittsperson», og baserer seg på en standard utregning der hver av de estimerte koeffisientverdiene blir multiplisert med gjennomsnittsverdien for tilhørende forklaringsvariabel (x). Disse summeres så sammen med konstantleddet i tråd med den estimerte regresjonslikningen:
Merk at ved logaritmiske modeller gitt ved logit og probit, kan ikke koeffisientestimatene b tolkes som marginaleffekter på samme måte som for regress. Predikert Y baserer seg derfor på følgende transformasjon:
-
logit:
-
probit:
(Merk: er den kumulative normalfordelingsfunksjonen)
Du kan også angi en dummyvariabel inni parentesen i margins(). Da vil du få returnert to ekstra linjer under modellestimatene, dvs. predikert Y-verdi for hver verdi av dummyvariabelen (verdiene 0 og 1). Du estimerer da predikert Y for hver av de to gruppene med verdien 0 og 1, der alle øvrige forklaringvariabler måles ved gjennomsnittsverdi. Merk at dummyvariabelen du benytter må også inngå i selve regresjonsmodellen. I praksis estimeres da «forventet verdi av Y for en gjennomsnittsperson i de respektive gruppene 0 og 1». Om man f.eks. bruker dummyvariabelen «mann», så måler man forventet verdi av Y for en gjennomsnittsmann og en gjennomsnittskvinne.
Eksempler:
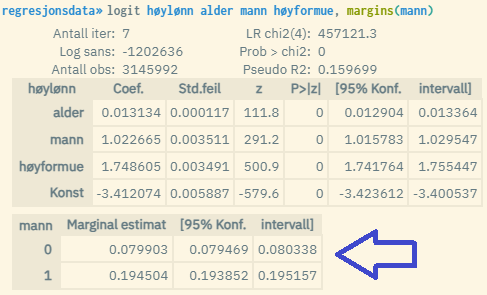
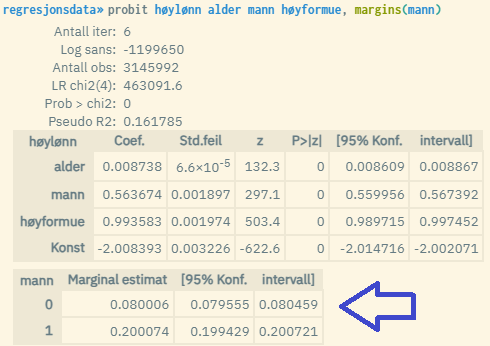
Merk at ved beregninger av predikerte Y-verdier, er det det winsoriserte gjennomsnittet som benyttes, dvs. et gjennomsnitt som potensielt kan være påvirket av winsorisering av ekstremverdier. I praksis betyr dette at gjennomsnittsverdiene som benyttes ved beregningene av predikerte verdier er noe lavere enn de faktiske i en del tilfeller. Du kan lese mer om winsorisering her: https://microdata.no/manual/konfidensialitet#tiltak-2-winsorisering
Til forskjell fra logit-predict og probit-predict som genererer et datasett med predikerte verdier for hver enhet gitt de faktiske verdiene på forklaringsvariablene, beregner margins-opsjonen predikerte Y-verdier målt ved gjennomsnittet for de respektive forklaringsvariabler målt over hele populasjonen. Når man bruker kommandoen summarize til å vise gjennomsnittet av predikert Y-verdi basert på datasettet med individuelle predikerte verdier generert gjennom -predict-kommandoene, vil derfor ikke disse samsvare med verdiene som rapporteres gjennom margins-opsjonen.